
Why do you have to manually enter information after uploading a resume?
October 2021
October 2021

Scrolling through social media, you saw the great job opportunity and decided to apply. You have spent multiple hours figuring out how to present yourself in several pages of text and now you are ready to hit that “Apply Now” button. Resume is uploaded and it prompts you to enter your name, contact information, education, every single job title, employment date, etc.
But, wait a second it is all in the resume already.
As I became a Data Scientist in a startup that provides recruitment solutions for companies, I have spent numerous hours reading TalentLyft Blog in order to get a better understanding of the new industry I got into. Because we have noticed that one of the most time consuming tasks of the recruiter is manually reading through a pile of resumes, building a resume parser was the first major project I have been working on. I will walk you through the lessons learned in the creation of an internal parser.

Source: link
“Resume parsing is the automated process of extracting structured information from a free form resume.”
Reading resumes is an easy task for the human eye because these documents are semi-structured, usually separated in sections and have layouts that make it easy to quickly identify important information. But, because each corporate job opening attracts 250 resumes (according to Glassdoor) recruiters have to speed through resumes in order to keep up with the applications. With the reduced concentration and shorter time on each resume, it is easy to miss good candidates.
Resume parsing is the automated process of extracting structured information from a free form resume. The resume is imported into parsing software and the information is extracted so that it can be sorted and searched.
Recruiters or HR professionals commonly use resume parsing software, usually a part of Applicant Tracking Systems software (ATS), as a step in the hiring process to create an easier, convenient, and more efficient experience for all candidates. Because of electronically gathered, stored, and organized information found within resumes they are able to hire the right candidate faster than would without using a parser.
There are endless ways to write a resume, some are better and some are worse. In reality, you will get applications in different formats such as .txt, .doc, .docx, .pdf, etc. Each of those formats has commonly used templates, but not all templates are straightforward to read. For eg. one can find tables, graphics, columns in a resume, and every such entity needs to be read in a different manner.
To develop a resume parser you need to extract text from all types of resumes. This part can already be tricky. For instance, we have tried one tool that omitted all the ‘\n’ characters, so the text extracted was something like a chunk of text. Thus, it was difficult to separate them into multiple sections.
The hardest part comes after the text is extracted.
Naive approach to structuring a resume is to build a rule-based system to extract information. The system will identify words, patterns and phrases in the text on which it will apply simple heuristic algorithms to the text they find around these words.
This approach is the simplest and the least accurate. It is only good enough for scanning something like a zip code and assuming the surrounding words are an address. Or it would scan for “First Name:” and assume that the text following this keyword will be the first name of the candidate.
First upgrade was to create a grammar-based parsing tool that will use a large number of grammatical rules. They will combine specific words and phrases together to make complex structures as a way to capture the exact meaning of every sentence within a resume. To build such a tool, there was a lot of manual encoding needed. That was usually done by skilled language engineers. Commonly, they used regular expression or in short regex which is a string of text that allows you to create patterns that help match, locate, and manage text.
One of the most useful applications of regex in resume parsing is finding email addresses. The following image shows what set of rules a certain string has to satisfy in order to be in e-mail form.

Source: link
To detect and extract such a pattern, appropriate regular expression has to be created. One example can be found in the next picture. (Read more about regex: link)
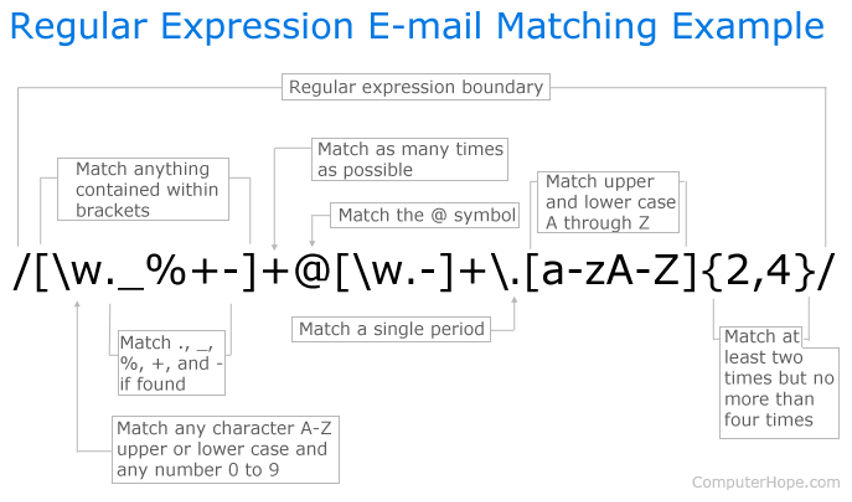
Source: link
As it turned out, there is a lot of variability and ambiguity in the language used in resumes and this approach didn’t work. Some people would put the date in front of the title of the resume, some people do not put the duration of the work experience or some people do not list down the company in the resumes. This makes the resume parser even harder to build, as there are no fixed patterns to be captured. To conquer this beast, we had to bring big guns.
Since modern machine learning and deep learning in particular, requires a huge amount of annotated data to outperform traditional methods, we had to gather data. The problem was that resumes contain sensitive data and almost none are publicly available. In particular, there is no annotated dataset of resumes. Without the dataset, there is no deep learning.
We have decided to spend our resources to manually create and annotate the dataset and the decision was great. We have spent more than 6 months with multiple members of the team, labeling the resumes with the tool called INCEpTION which enabled us fast, safe and reliable annotation. In parallel with the annotation, we have developed deep learning models to actively predict the labels of future unlabeled resumes. That way, as we labeled more resumes, our recommendations were better and our labeling became faster. Another benefit was that we could notice common patterns of where the model usually failed and fix them on the next iteration. For example, after ~250 labeled resumes we have developed our first recommender. In theory it worked well, but in practice it always made mistakes at the beginning of the row. It turned out that we developed a recommender that ignored the new line character “\n”. Losing this information, it performed significantly worse that it should.

INCEpTION tool
Resume parser can be framed as the variant of the common problem in Natural Language Processing (NLP) called Named Entity Recognition (NER). “Named-entity recognition (NER) is a subtask of information extraction that seeks to locate and classify named entities mentioned in unstructured text into pre-defined categories such as person names, organizations, locations, medical codes, time expressions, quantities, monetary values, percentages, etc.” (Wikipedia)
Each word of resume (or subword, aka. token) model has to classify in one of the categories: SCHOOL_NAME, DEGREE, EDU_DESCRIPTION, TIME_SPAN, COMPANY_NAME, WORK_DESCRIPTION, JOB_TITLE, CERTIFICATE, SKILLS or OTHER.
If we frame our task as a NER problem, in theory, we can use the best practices from solving NER problems and apply it to our parser. That is exactly what we did. First we tried models based on BiLSTM that performed best at the time in NER problems.
But then, the research paper “Attention is all you need” created a huge shift in the NLP world and it’s variants became state-of-the-art for almost every NLP problem, including NER. The most popular were Transformer based models (like BERT) that were really good at understanding the context in the text.
For example:
“The animal didn’t cross the street because it was too tired.”
“The animal didn’t cross the street because it was too wide.”
In the first sentence, the word “it” refers to the “animal” and in the second sentence “it” is referred to the “street”.
Understanding of structures like this lead to significant improvements of our parser. Drawback is that these models are usually really big and it takes a lot of time to train them and they require a lot of compute power. Fortunately, there were a lot of improvements since we first started with Transformer based models and today we are using models that are more lightweight and optimized for production (for example DistilBert, Tiny-Bert, etc.).
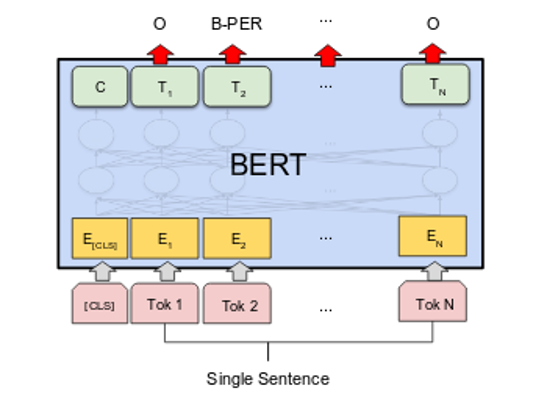
Source: link
When you switch job positions, make sure that you invest a good amount of time researching the industry. It will give you a much needed understanding of problems in industry and help you craft the best approach of solving them.
In our case, we wanted to create a resume parser to help candidates with job applications and to help recruiters with candidate selection. Another benefit was that lessons learned while developing an in-house resume parser were easily applied on developing a job description parser. Using adequate parts of the resume and job description enabled us to create a candidate recommender system to even further improve candidate selection.
One last thought, always keep learning. If you stay on top of current state-of-the-art tools, that way you will think of creative ideas on how to solve problems.
Ivan received his MS degree in Mathematics (mag. math.) in 2020 from the Department of Mathematics at the Josip Juraj Strossmayer University of Osijek. While studying, he acquired his knowledge of machine learning through courses, books and online blogs. He put his theoretical knowledge into practice on his own projects, which were mostly in the field of computer vision. In 2019, he starts working as a Data Scientist at TalentLyft, where he specializes in natural language processing and statistical data processing.